auc作為分類的重要評估指標,在此總結一下。
AUC(Area Under Curve)被定義為ROC曲線下與坐標軸圍成的面積。因此在計算auc之前,需要先熟悉roc曲線。
ROC(receiver operating characteristic curve)接收者操作特征曲線,是由二戰中的電子工程師和雷達工程師發明用來偵測戰場上敵軍載具(飛機、船艦)的指標,屬於信號檢測理論。
ROC曲線的橫坐標是偽陽性率(也叫假正類率,False Positive Rate),縱坐標是真陽性率(真正類率,True Positive Rate),相應的還有真陰性率(真負類率,True Negative Rate)和偽陰性率(假負類率,False Negative Rate)。這四類指標的計算方法如下:
(1)偽陽性率(FPR):判定為正例卻不是真正例的概率,即真負例中判為正例的概率
(2)真陽性率(TPR):判定為正例也是真正例的概率,即真正例中判為正例的概率(也即正例召回率)
(3)偽陰性率(FNR):判定為負例卻不是真負例的概率,即真正例中判為負例的概率。
(4)真陰性率(TNR):判定為負例也是真負例的概率,即真負例中判為負例的概率。
看定義似乎,不夠直觀,我們上圖。
其實就是4個比率:真陽,假陽,真陰,假陰

TPR:正樣本中的正確判別率,這些陽性被報警找瞭出來。(相對實際正樣本比例)
{frac{TP}{TP+FN}}
FPR:負樣本中的錯判率(假警報率),這些陰性的被報警成陽性。(相對實際負樣本的比率)
frac{FP}{FP+TN}
TNR(也稱為specificity):
frac{TN}{FP+TN}=1-FPR
FNR:
frac{FN}{TP+FN}=1-TPR
ACC:
frac{TP+TN}{TP+FP+FN+TN}
recall:
qquadqquadqquad {frac{TP}{TP+FN}}=TPR
precision:
qquadqquad frac{TP}{TP+FP}
而roc曲線就是根據TPR和FPR的坐標點繪制出來的。
在一個二分類模型中,對於所得到的連續結果,假設已確定一個閥值,比如說 0.6,大於這個值的實例劃歸為正類,小於這個值則劃到負類中。如果減小閥值,減到0.5,固然能識別出更多的正類,也就是提高瞭識別出的正例占所有正例 的比類,即TPR,但同時也將更多的負實例當作瞭正實例,即提高瞭FPR。
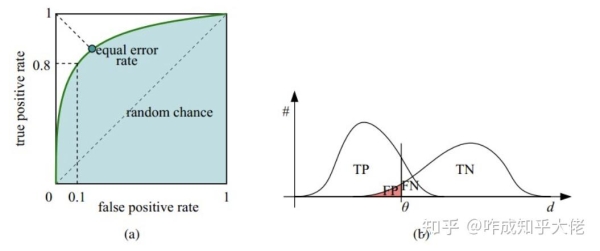
ROC曲線上的每一個點對應於一個threshold,對於一個分類器,每個threshold下會有一個TPR和FPR。比如Threshold最大時,TP=FP=0,對應於原點;Threshold最小時,TN=FN=0,對應於右上角的點(1,1)
(b)隨著閾值theta增加,TP和FP都減小,TPR和FPR也減小,ROC點向左下移動;
而auc就是roc曲線與下方坐標軸圍成的面積。那如何求這個面積呢?
第一種方法:
按照定義求面積,但這種方法顯得有點不直觀,而且不方便操作,因為首先你要改變閾值,畫出來很多點。而且這麼做有個缺點,就是當多個測試樣本的的預測score相等的時候,我們調整一下閾值,得到的曲線不是一個階梯往上或者往右的延展,而是斜著向上形成,這樣會形成一個梯形。此 時,我們就需要計算這個梯形的面積。由此,我們可以看到,用這種方法計算AUC實際上是比較麻煩的
第二種方法:
一個關於AUC的很有趣的性質是,它和Wilcoxon-Mann-Witney Test是等價的。而Wilcoxon-Mann-Witney Test就是測試任意給一個正類樣本和一個負類樣本,正類樣本的score有多大的概率大於負類樣本的score。有瞭這個定義,我們就得到瞭另外一中計 算AUC的辦法:得到這個概率。我們知道,在有限樣本中我們常用的得到概率的辦法就是通過頻率來估計之。這種估計隨著樣本規模的擴大而逐漸逼近真實值。這 和上面的方法中,樣本數越多,計算的AUC越準確類似,也和計算積分的時候,小區間劃分的越細,計算的越準確是同樣的道理。
這種方式還有一種理解,或者說是求頻率的方法:
我們畫坐標圖,橫坐標代表負樣本,有n格,縱坐標代表正樣本,有m格,把所有樣本預測值從大到小排序,從原點開始,遇到負樣本向右走一個格,遇到正樣本向上走1個格,恰恰走m+n個格子。路徑下的格子數除以mn就是auc,前提是沒有相同預測score的樣本。
第三種方法:
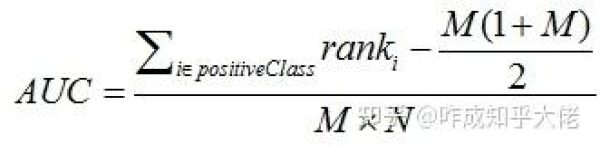
這個公式如何理解呢?在此解釋一下:
1、為瞭求的組合中正樣本的score值大於負樣本,如果所有的正樣本score值都是大於負樣本的,那麼第一位與任意的進行組合score值都要大,我們取它的rank值為n,但是n-1中有M-1是正樣例和正樣例的組合這種是不在統計范圍內的(為計算方便我們取n組,相應的不符合的有M個),所以要減掉,那麼同理排在第二位的n-1,會有M-1個是不滿足的,依次類推,故得到後面的公式M*(M+1)/2,我們可以驗證在正樣本score都大於負樣本的假設下,AUC的值為1
2、根據上面的解釋,不難得出,rank的值代表的是能夠產生score前大後小的這樣的組合數,但是這裡包含瞭(正,正)的情況,所以要減去這樣的組(即排在它後面正例的個數),即可得到上面的公式
另外,特別需要註意的是,再存在score相等的情況時,對相等score的樣本,需要 賦予相同的rank(無論這個相等的score是出現在同類樣本還是不同類的樣本之間,都需要這樣處理)。具體操作就是再把所有這些score相等的樣本 的rank取平均。然後再使用上述公式。註意這裡的取平均是先按照正常順序排序,之後對相鄰的分數相同的樣本排名 取平均。
舉例:
有7個樣本: 4個正樣本,3個負樣本
1)我們首先按每個正樣本後面有幾個它大於的負樣本進行計算(score為0.9的正樣本,後面有3個負樣本,score為0.7的兩個正樣本,後面各有1.5個負樣本,0.7的負樣本因為和他們同分,算0.5 個):
auc=frac{3+1.5+1.5}{3*4}=0.5
2)按照上面的rank公式進行計算:
auc=frac{7+4+4+1-frac{4*5}{2}}{3*4}=0.5
結果保持一致
計算代碼:
import numpy as np
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
def auc_calculate(labels,preds,n_bins=100):
postive_len = sum(labels) #正樣本數量(因為正樣本都是1)
negative_len = len(labels) - postive_len #負樣本數量
total_case = postive_len * negative_len #正負樣本對
pos_histogram = [0 for _ in range(n_bins)]
neg_histogram = [0 for _ in range(n_bins)]
bin_width = 1.0 / n_bins
for i in range(len(labels)):
nth_bin = int(preds[i]/bin_width)
if labels[i]==1:
pos_histogram[nth_bin] += 1
else:
neg_histogram[nth_bin] += 1
accumulated_neg = 0
satisfied_pair = 0
for i in range(n_bins):
satisfied_pair += (pos_histogram[i]*accumulated_neg + pos_histogram[i]*neg_histogram[i]*0.5)
accumulated_neg += neg_histogram[i]
return satisfied_pair / float(total_case)
if __name__ == '__main__':
y = np.array([1,0,0,0,1,0,1,0,])
pred = np.array([0.9, 0.8, 0.3, 0.1,0.4,0.9,0.66,0.7])
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
print("sklearn:",auc(fpr, tpr))
print("驗證:",auc_calculate(y,pred))



